Amazon Web Services
2006: Amazon launched Amazon Web Service (AWS) on a utility computing basis although the initial released dated back to July 2002.
Amazon Web Services (AWS) is a collection of remote computing services (also called web services) that together make up a cloud computing platform, offered over the Internet by Amazon.com.
The most central and well-known of these services are Amazon EC2 (Elastic Compute Cloud )and Amazon S3 (Simple Storage Service).
Book:
Amazon Web Services is based on SOA standards, including HTTP, REST, and SOAP transfer protocols, open source and commercial operating systems, application servers, and browser-based access.
Topics:
1. Amazon EMR
3. Amazon Elasticsearch Service
1). Amazon EMR (Elastic MapReduce)
· Amazon EMR is a Web Service that makes it easy to Process Large Amounts Of Data efficiently.
· Amazon EMR uses Hadoop Processing combined with several AWS products to do such tasks as:
1. Web Indexing,
2. Data Mining,
3. Log File Analysis,
4. Machine Learning,
5. Scientific Simulation, and
6. Data Warehousing.
** MapReduce is a programming model for processing large data sets with a parallel, distributed algorithm on a cluster.
Amazon EMR releases are packaged using a system based on Apache BigTop, which is an open source project associated with the Hadoop ecosystem.
In addition to Hadoop and Spark Ecosystem projects, each Amazon EMR release provides components which enable cluster and resource management, interoperability with other AWS services, and additional configuration optimizations for installed software.
Each Amazon EMR release contains several distributed applications available for installation on your cluster.
When you choose to install an application using the console, API, or CLI, Amazon EMR installs and configures this set of components across nodes in your cluster.
The following applications are supported for this release: Ganglia, Hadoop, Hive, Hue, Mahout, Oozie-Sandbox, Pig, Presto-Sandbox, Spark, and Zeppelin-Sandbox.
Apache Hadoop
· Apache Hadoop is an open-source Java software framework that supports Massive Data Processing Across A Cluster Of Instances.
· It can run on a single instance, or thousands of instances.
· Hadoop uses a Programming Model called MapReduce to distribute processing across multiple instances.
· It also implements a Distributed File System called HDFS that stores data across multiple instances.
Hadoop monitors the health of instances in the cluster, and can recover from the failure of one or more nodes.
In this way, Hadoop provides increased processing and storage capacity, as well as high availability.
Major Players and Vendors for Hadoop:
1. Cloudera
2. Hortonworks
3. MapR
4. Amazon
5. Microsoft
Apache Hive
· Data Warehouse Infrastructure developed by Facebook.
· Data summarization, query, and analysis. It’s provides SQL-like language (not SQL92 compliant): HiveQL.
· Hive is an open-source, Data Warehouse, and Analytic Package that runs on top of Hadoop.
· Hive scripts use an SQL-like language called Hive QL (query language) that abstracts the MapReduce programming model and supports typical data warehouse interactions.
· Hive enables you to avoid the complexities of writing MapReduce programs in a lower level computer language, such as Java.
· Hive extends the SQL paradigm by including serialization formats and the ability to invoke mapper and reducer scripts.
· In contrast to SQL, which only supports primitive value types (such as dates, numbers, and strings), values in Hive tables are structured elements, such as JSON objects, any user-defined data type, or any function written in Java.
How Amazon EMR Hive Differs from Apache Hive: From Book
Apache Pig
· Apache Pig, a Programming Framework you can use to Analyze & Transform large data sets.
· Amazon EMR supports several versions of Pig.
· Pig is an open-source, Apache library that runs on top of Hadoop.
· The library takes SQL-like commands written in a language called Pig Latin and converts those commands into MapReduce jobs.
· You do not have to write complex MapReduce code using a lower level computer language, such as Java.
· You can execute Pig commands interactively or in batch mode.
· To use Pig interactively, create an SSH connection to the master node and submit commands using the Grunt shell.
· To use Pig in batch mode, write your Pig scripts, upload them to Amazon S3, and submit them as cluster steps.
· Pig provides an Engine For Executing Data Flows In Parallel on Hadoop.
· It includes a language, Pig Latin, for expressing these data flows.
· Pig runs on Hadoop. It makes use of both the HDFS, and Hadoop’s processing system, MapReduce.
· Pig uses MapReduce to execute all of its data processing. It compiles the Pig Latin scripts that users write into a series of one or more MapReduce jobs that it then executes.
Note: Pig Latin looks different from many of the programming languages you have seen. There are no if statements or for loops in Pig Latin. This is because traditional procedural and object-oriented programming languages describe control flow, and data flow is a side effect of the program. Pig Latin instead focuses on data flow.
Apache Spark
· Apache Spark is a Cluster Framework and Programming Model that helps you process data.
· Similar to Apache Hadoop, Spark is an open-source, Distributed Processing System commonly used for Big Data workloads.
· However, Spark has several notable differences from Hadoop MapReduce. Spark has an optimized Directed Acyclic Graph (DAG) execution engine and actively caches data In-Memory, which can boost performance especially for certain algorithms and interactive queries.
· Spark natively supports applications written in Scala, Python, and Java and includes several tightly integrated libraries for SQL (Spark SQL), machine learning (MLlib), stream processing (Spark Streaming), and graph processing (GraphX). These tools make it easier to leverage the Spark framework for a wide variety of use cases.
· Spark can be installed alongside the other Hadoop applications available in Amazon EMR, and it can also leverage the EMR File System (EMRFS) to directly access data in Amazon S3.
· Hive is also integrated with Spark. So you can use a HiveContext object to run Hive scripts using Spark. A Hive context is included in the spark-shell as sqlContext.
· Spark is a framework for writing fast, distributed programs.
· Spark is built on top of the HDFS. However, Spark provides an easier to use alternative to Hadoop MapReduce and offers performance up to 10 times faster than Hadoop MapReduce for certain applications.
Spark solves similar problems as Hadoop MapReduce does but with a fast in-memory approach and a clean functional style API.
· With its ability to integrate with Hadoop and inbuilt tools for Interactive Query Analysis (Shark), large-scale graph processing and analysis (Bagel), and real-time analysis (Spark Streaming), it can be interactively used to quickly process and query big data sets.
· To make programming faster, Spark provides clean, concise APIs in Scala, Java and Python.
· You can also use Spark interactively from the Scala and Python shells to rapidly query big datasets.
· Spark is also the engine behind Shark, a fully Apache Hive-compatible data warehousing system that can run 100x faster than Hive.
Hue (Hadoop User Experience)
· Hue is an open-source, Web-Based, Graphical User Interface for use with Amazon EMR and Apache Hadoop.
· Hue groups together several different Hadoop ecosystem projects into a configurable interface for your Amazon EMR cluster.
· Amazon has also added customizations specific to Hue in Amazon EMR releases.
· Launch your cluster using the Amazon EMR console and you can interact with Hadoop and related components on your cluster using Hue.
Hue on Amazon EMR supports the following:
· Amazon S3 and HDFS Browser—With the appropriate permissions, you can browse and move data between the ephemeral HDFS storage and S3 buckets belonging to your account.
· Hive—Run interactive queries on your data. This is also a useful way to prototype programmatic or batched querying.
· Pig—Run scripts on your data or issue interactive commands.
· Oozie—Create and monitor Oozie workflows.
· Metastore Manager—View and manipulate the contents of the Hive metastore (import/create, drop, and so on).
· Job browser—See the status of your submitted Hadoop jobs.
· User management—Manage Hue user accounts and integrate LDAP users with Hue.
· AWS Samples—There are several "ready-to-run" examples, which process sample data from various AWS services using applications in Hue. When you log in to Hue, you are taken to the Hue Home application where the samples are pre-installed.
Ganglia
· The Ganglia open source project is a scalable, distributed system designed to Monitor Clusters and Grids while minimizing the impact on their performance.
· When you enable Ganglia on your cluster, you can generate reports and view the performance of the cluster as a whole, as well as inspect the performance of individual node instances.
· Ganglia is also configured to ingest and visualize Hadoop and Spark metrics
· When you view the Ganglia web UI in a browser, you see an overview of the Cluster’s Performance, with graphs detailing the load, memory usage, CPU utilization, and network traffic of the cluster.
Apache Mahout
· Machine Learning Library and Math Library, on top of MapReduce.
· Mahout is a machine learning library with tools for clustering, classification, and several types of recommenders, including tools to calculate most-similar items or build item recommendations for users.
· Mahout employs the Hadoop framework to distribute calculations across a cluster, and now includes additional work distribution methods, including Spark.
· AWS Data Pipeline is a web service that you can use to Automate the Movement and Transformation of data.
· With AWS Data Pipeline, you can define data-driven workflows, so that tasks can be dependent on the successful completion of previous tasks.
The following components of AWS Data Pipeline work together to manage your data:
· Pipeline Definition - Specifies the business logic of your data management.
· Pipeline - Schedules and runs Tasks.
· Task Runner - Polls for tasks and then performs those tasks.
For example, you can use AWS Data Pipeline to archive your web server's logs to Amazon S3 each day and then run a weekly Amazon EMR cluster over those logs to generate traffic reports. AWS Data Pipeline schedules the daily tasks to copy data and the weekly task to launch the Amazon EMR cluster. AWS Data Pipeline also ensures that Amazon EMR waits for the final day's data to be uploaded to Amazon S3 before it begins its analysis, even if there is an unforeseen delay in uploading the logs.

AWS Data Pipeline works with the following services to store data.
· Amazon DynamoDB — Provides a fully-managed NoSQL database with fast performance at a low cost.
· Amazon RDS — Provides a fully-managed Relational database that scales to large datasets.
· Amazon Redshift — Provides a fast, fully-managed, Petabyte-Scale data warehouse that makes it easy and cost-effective to analyze a vast amount of data
· Amazon S3 — Provides secure, durable, and highly-scalable Object Storage.
AWS Data Pipeline works with the following compute services to transform data.
· Amazon EC2 — Provides resizeable computing capacity—literally, servers in Amazon's data centers—that you use to build and host your software systems.
· Amazon EMR — Makes it easy, fast, and cost-effective for you to distribute and process vast amounts of data across Amazon EC2 servers, using a framework such as Apache Hadoop or Apache Spark.
3). Amazon Elasticsearch Service (ES)
· Amazon ES is a managed service that makes it easy to Deploy, Operate, and Scale Elasticsearch Clusters in the AWS cloud.
· Elasticsearch is a popular open-source Search and Analytics Engine for use cases such as log analytics, real-time application monitoring, and click stream analytics.
· Amazon ES also offers security options, high availability, data durability, and direct access to the Elasticsearch API.
· Amazon Elasticsearch Service offers the following benefits of a managed service:
1. Cluster scaling options
2. Self-healing clusters
3. Replication for high availability
4. Data durability
5. Security
6. Node monitoring
Amazon Elasticsearch Service provides the following features:
· Multiple configurations of CPU, memory, and storage capacity, known as Instance Types
· Storage volumes for your data using Amazon Elastic Block Store, known as Amazon EBS volumes
· Multiple geographical locations for your resources, known as regions and Availability Zones
· Cluster node allocation across two Availability Zones in the same region, known as Zone Awareness
· Security with IAM-based access control
· Dedicated master nodes to improve cluster stability
· Domain snapshots to back up and restore Amazon ES domains, and replicate domains across Availability Zones
· Kibana for data visualization
· Integration with Amazon CloudWatch for monitoring Amazon ES domain metrics
· Integration with AWS CloudTrail for auditing configuration API calls to Amazon ES domains
4). Amazon Kinesis Steams
· Amazon Kinesis is a managed service that Scales Elastically For Real-Time Processing Of Streaming Data at a massive scale.
· The service collects & process large streams of data records in real time, by multiple data-processing applications that can be run on Amazon EC2 instances.
· Use Amazon Kinesis Streams to Collect And Process Large Streams Of Data Records in Real Time.
· You'll create data-processing applications, known as Amazon Kinesis Streams applications.
· A typical Amazon Kinesis Streams application reads data from an Amazon Kinesis stream as data records.
· These applications can use the Amazon Kinesis Client Library, and they can run on Amazon EC2 instances.
· The processed records can be sent to dashboards, used to generate alerts, dynamically change pricing and advertising strategies, or send data to a variety of other AWS services.
You can use Streams for rapid and continuous data intake and aggregation. The type of data used includes:
· IT infrastructure log data,
· Application logs,
· Social media,
· Market data feeds, and
· Web clickstream data
Because the response time for the data intake and processing is in real time, the processing is typically lightweight.
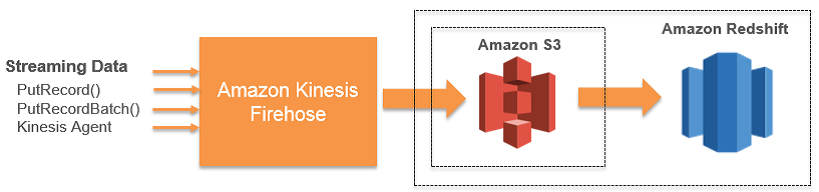
5). Amazon Kinesis Firehose
· Amazon Kinesis Firehose is a fully managed service for Delivering Real-Time Streaming Data to destinations such as Amazon S3 and Amazon Redshift.
· Firehose is part of the Amazon Kinesis streaming data family, along with Amazon Kinesis Streams.
· With Firehose, you do not need to write any applications or manage any resources.
· You configure your data producers to send data to Firehose and it automatically delivers the data to the destination that you specified.
6). Amazon Machine Learning (ML)
· Amazon Machine Learning makes it easy for developers to Build Smart Applications, including applications for fraud detection, demand forecasting, targeted marketing, and click prediction.
· The powerful algorithms of Amazon ML create ML models by finding patterns in your existing data.
· The service uses these models to process new data and generate predictions for your application.
Amazon ML provides Visualization Tools and Wizards that guide you through the process of creating ML models without having to learn complex ML algorithms and technology.
Once your models are ready, Amazon ML makes it easy to obtain predictions for your application using simple APIs, without having to implement custom prediction generation code, or manage any infrastructure.
AML Key Concepts:
• Datasources contain metadata associated with data inputs to Amazon ML
• ML models generate predictions using the patterns extracted from the input data
• Evaluations measure the quality of ML models
• Batch predictions asynchronously generate predictions for multiple input data observations
• Real-time predictions synchronously generate predictions for individual data observations
· Amazon Redshift is a fast, fully managed, Petabyte-Scale Data Warehouse service that makes it simple and Cost-Effective To Efficiently Analyze All Your Data using your existing business intelligence tools.
· It is optimized for datasets ranging from a few hundred gigabytes to a petabyte or more and costs less than $1,000 per terabyte per year, a tenth the cost of most traditional data warehousing solutions.
· An Amazon Redshift data warehouse is a collection of computing resources called Nodes, which are organized into a group called a Cluster.
· Each cluster runs an Amazon Redshift engine and contains one or more databases.
· The Amazon Redshift service manages all of the work of setting up, operating, and scaling a data warehouse.
· These tasks include provisioning capacity, monitoring and backing up the cluster, and applying patches and upgrades to the Amazon Redshift engine.
http://docs.aws.amazon.com/redshift/latest/mgmt/overview.html
Regards,
Arun Manglick
No comments:
Post a Comment